语料处理后\audios\wavs目录wav时长秒, 语料质量 取0-100 以软件切分后自己评估 , ti算量文件数字。以我跑的多个模型效果参考,如果计算评估分大于40就说明质量接近原声90%以上了 =2.2*(C2/600)^0.35*(D2/10)^0.6*(G2/1000)^0.4
提高模型质量方式: 1.增加语料 处理前语音应该大于30分钟, 2.提高语音质量,可提前编辑删除不好分离人声有杂音、破音的语句、编辑修正语音与机转录文字准确度 3.多跑次数 !
不错
根据我跑的模型更新加强以下克隆相似估算算法,得出数字认为100人有多少人分辨不出这是克隆生成的声音。
根据算法,采用1-2小时音频处理,会采集到处理后\audios\wavs目录wav时长秒1800-3600秒有效语料。
自己给语料质量评分,机器识别正确率15/音质50/响度5/音色10/情感10/语速一致性10
=F2^0.19*((I2/F2)^0.55D2/C2/100)^0.3((E2-30)/10)^0.61*(I2/C2/1000)^0.34/2
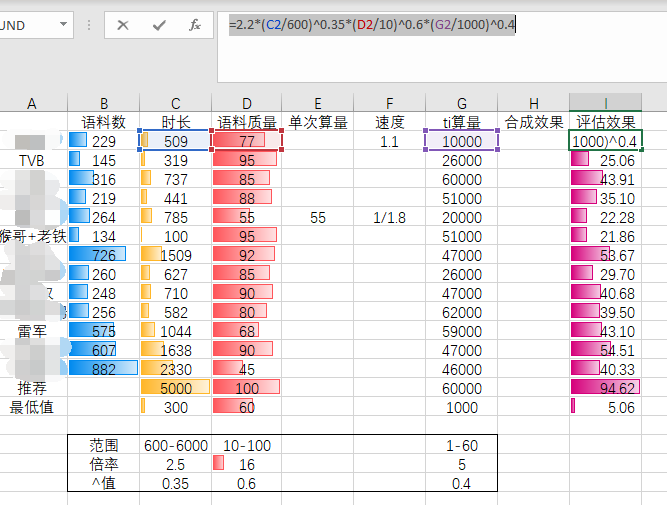


不错
根据我跑的模型更新加强以下克隆相似估算算法,得出数字认为100人有多少人分辨不出这是克隆生成的声音。
根据算法,采用1-2小时音频处理,会采集到处理后\audios\wavs目录wav时长秒1800-3600秒有效语料。
自己给语料质量评分,机器识别正确率15/音质50/响度5/音色10/情感10/语速一致性10
=F2^0.19*((I2/F2)^0.55D2/C2/100)^0.3((E2-30)/10)^0.61*(I2/C2/1000)^0.34/2
- 1
前往